
微软发布其基于纯视觉的 GUI 代理的屏幕解析工具 OmniParser 的更新,V2版本, OmniParser 旨在使任何大语言模型(LLM)能够作为 计算机使用代理,进行 图形用户界面(GUI)自动化。
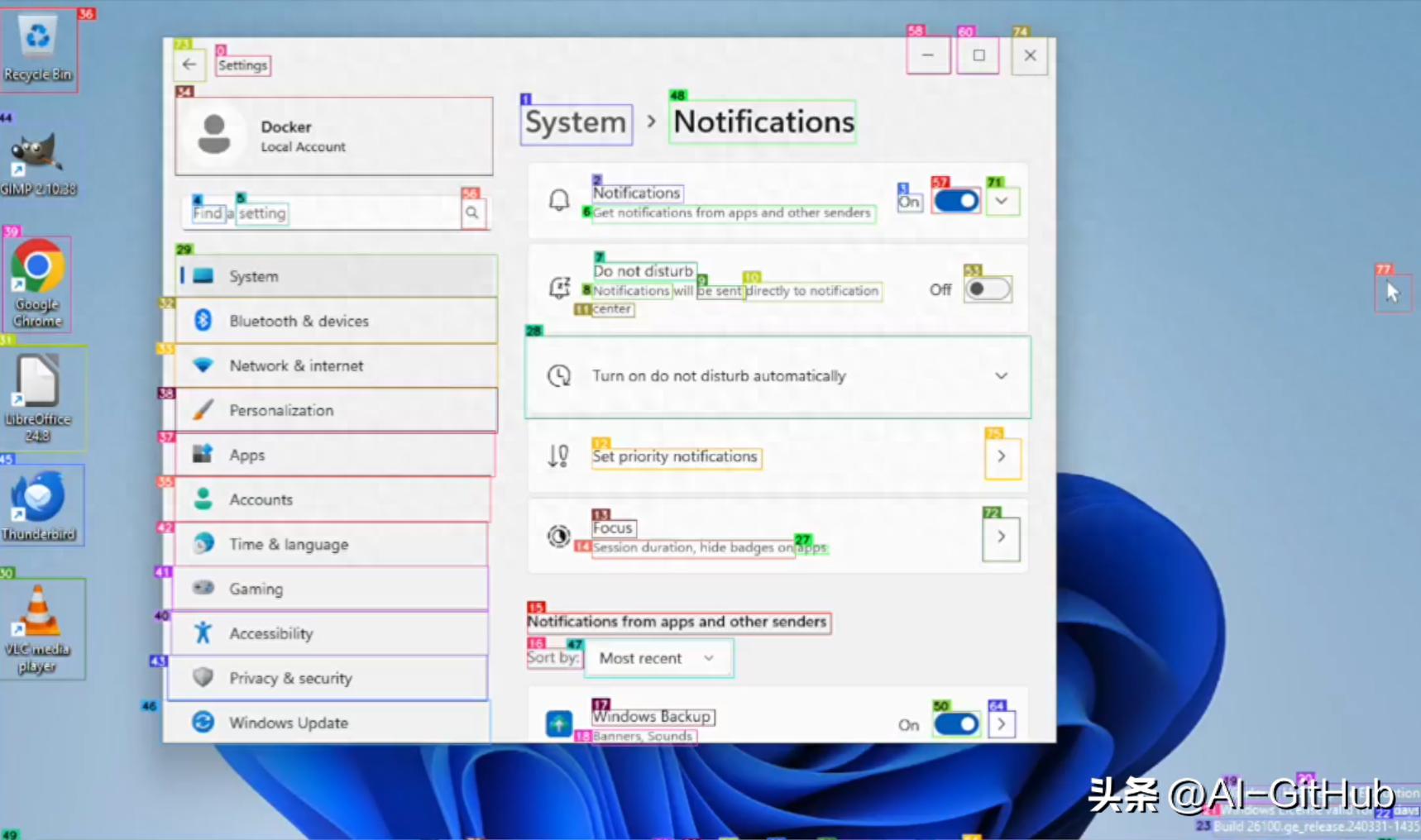
也就是帮助计算机理解和自动执行图形界面操作的工具,它可以让大型语言模型(如 GPT)识别屏幕上的按钮、图标等可交互元素,从而实现自动化任务。
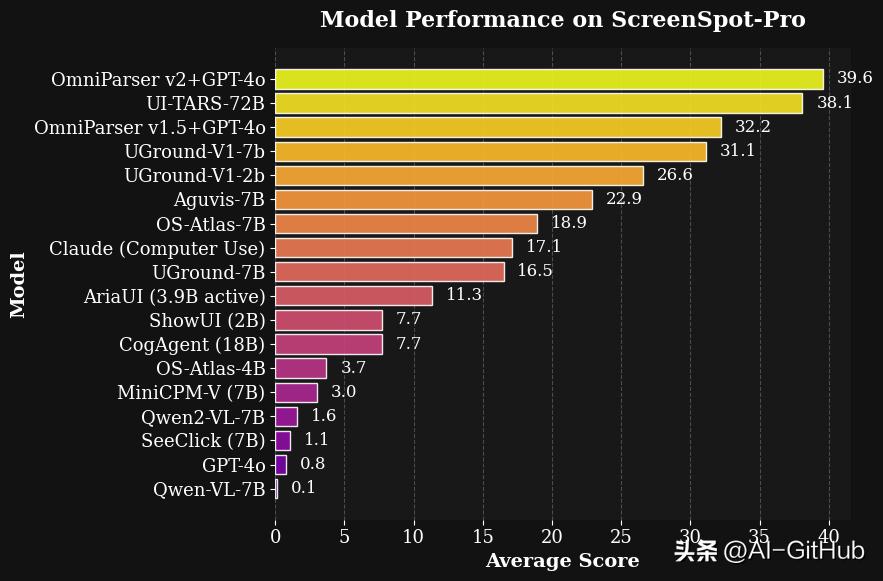
OmniParser V2 比之前的版本更加精准、快速,尤其在小图标和高分辨率屏幕的识别上表现更好。V2 在速度和功能上相较于 V1 提升了60%,并支持多种操作系统和应用程序图标识别。
OmniParser V2 的目标是将这些强大的语言模型与计算机操作结合起来。通过将 LLM 与 OmniParser 结合,系统可以自动化许多计算机使用任务,像是通过语言指令来控制计算机界面。这样,任何能够运行的 LLM 都能变成一个“计算机使用代理”,能够执行用户的指令,如:
- 点击、输入、拖拽等操作。
- 执行一些基于视觉信息的任务(比如读取图标、按钮等)。
简单来说,OmniParser V2 就是让 AI 不仅能理解语言,还能通过理解屏幕上的内容,像人一样去操作电脑,完成任务。
OmniParser V2 的主要改进:
- 提高精度:与其前身相比,OmniParser V2 在识别 小型可交互元素(如小图标)时的准确性更高。
- 加快速度:通过减少图标说明模型的图像大小,推理速度比之前快了60%。这意味着,OmniParser V2 在执行任务时能够更快速地响应。
- 增强数据集:OmniParser V2 使用了更大规模的训练数据,涵盖了更多交互元素的检测和图标功能描述数据,使其能够更好地理解和执行操作。
GitHub地址:https://github.com/microsoft/OmniParser/tree/master

